 by
by
With AVACloud, we're providing a hosted SaaS service for our GAEB & AVA .Net Libraries, a project calculation module & data exchange format for the construction industry.
Among the paid service, there are some free offerings for AVACloud for limited use cases. With that, users often convert from the various data formats to Excel. In our monitoring, we noticed some irregularities from the free service. Conversions usually take just tens or a few hundreds of milliseconds. But we had some that took about half an hour, way to long for any one user to be happy.
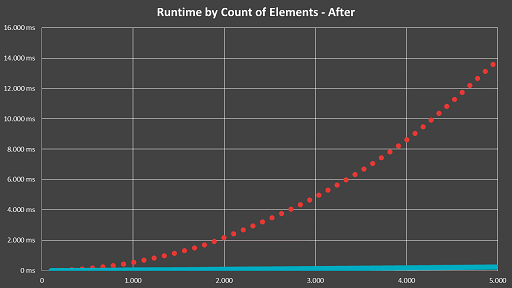
Luckily, we've been contact by the user and were asked for assistance. After a bit of investigation and profiling, we quickly found the culprit - we had a part in the conversion process that had O(n²) runtime:
The graph above shows the run time of the complete conversion process by the amount of elements within a parent container. It's a pretty nice O(n²) graph, at least visually, not so much for actual users😊
The thing is, this wasn't really noticed anytime before. In practice, service specifications for construction projects look like this:
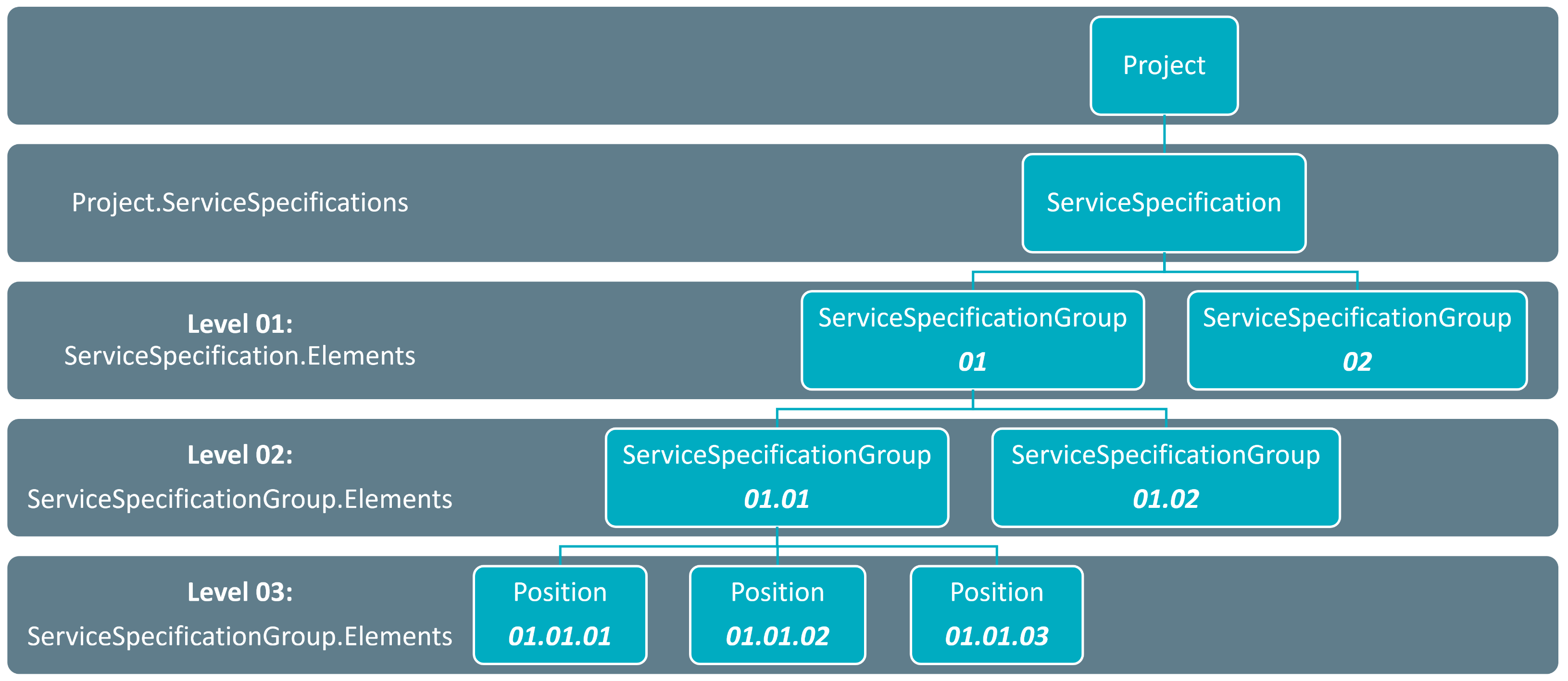
So while real construction projects often have up to a few hundred of positions, sometimes even a few thousand, they're structured in a tree so that each container itself only has at most tens of child elements.
The offending part of the code actually worked on the level of a single container. It did perform a validity check when adding a new element, by checking against all siblings. This wasn't a problem until one day, a customer had a single container with over 40.000 elements that really triggered this...
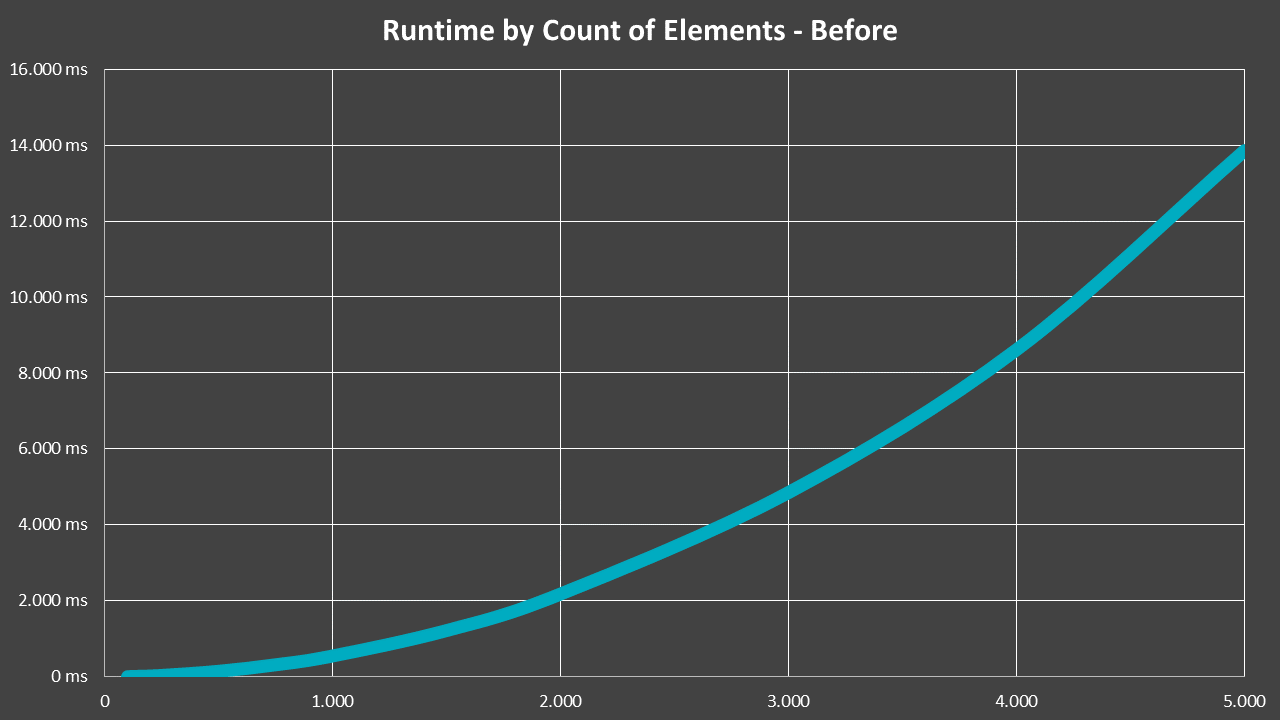
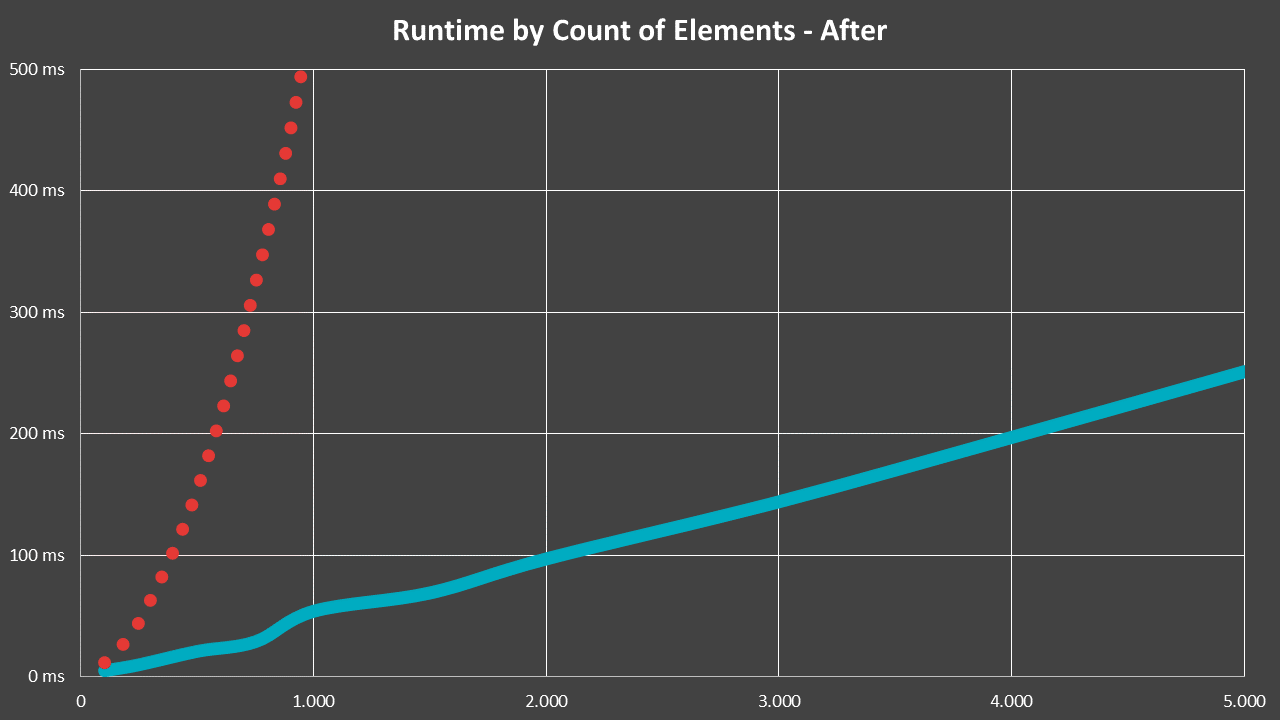
The fix was rather easy, it basically just amounted to introducing a cache. And thus, the performance quickly became linear:
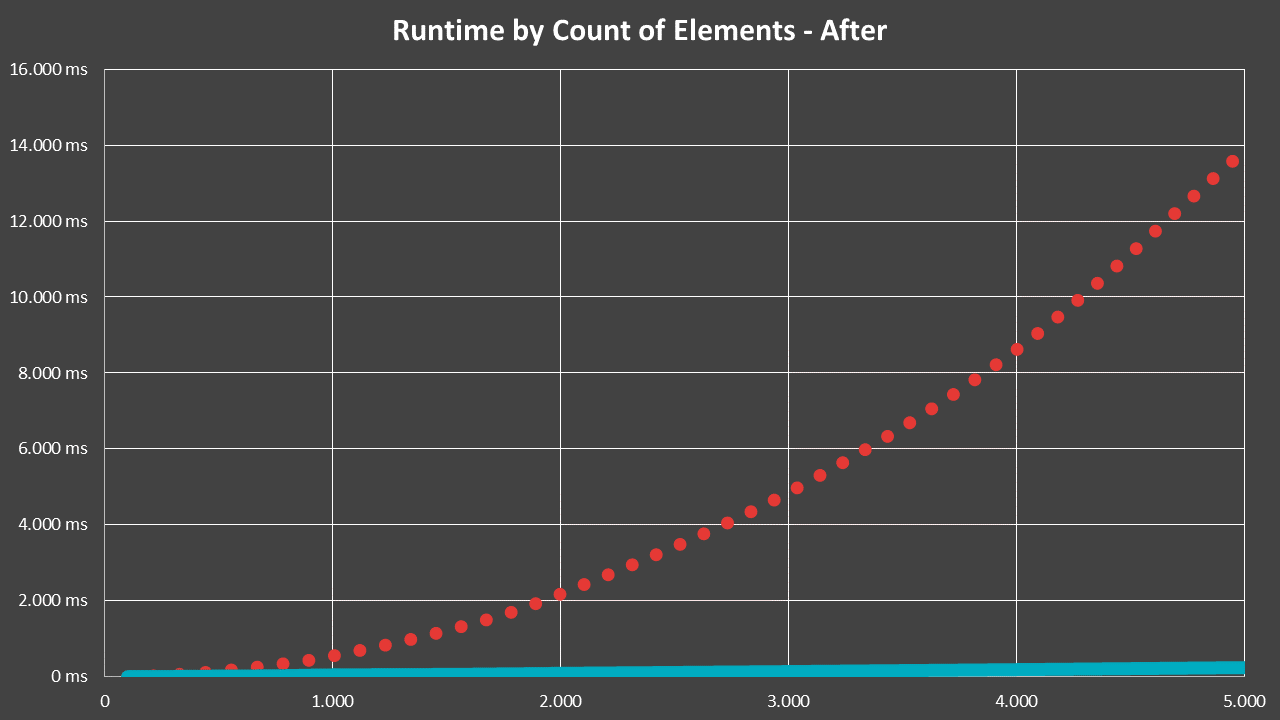
In that case, the dotted red line is the previous, O(n²) runtime, while blue represents the situation after the fix. Even more impressive is a zoomed view, which shows just how massive the difference from such an oversight can be:
In hindsight, the error was very obvious. It wasn't noticed because typical data sets were always small enough so this never really was a problem, until it one day was... Luckily, the fix could be implemented very quickly, and I got a satisfied user and some material for a blog post out of it😊
Happy optimizing!